Overview
MUSE is a text-to-music generation system built as a final project for the Parallel Computation course. It addresses the fundamental “one-to-many” problem in creative AI: a single text prompt like “a sad piano melody” can correspond to infinitely many valid musical interpretations.
The One-to-Many Problem
Traditional regression approaches predict the mean of possible outputs, resulting in blurry, mode-averaged music. MUSE instead models the full conditional distribution , enabling diverse, high-fidelity sampling.
| Approach | Output | Issue |
|---|---|---|
| Regression | Mean | Blurry, averaged |
| Generative | Diverse samples | ✓ Preserves creativity |
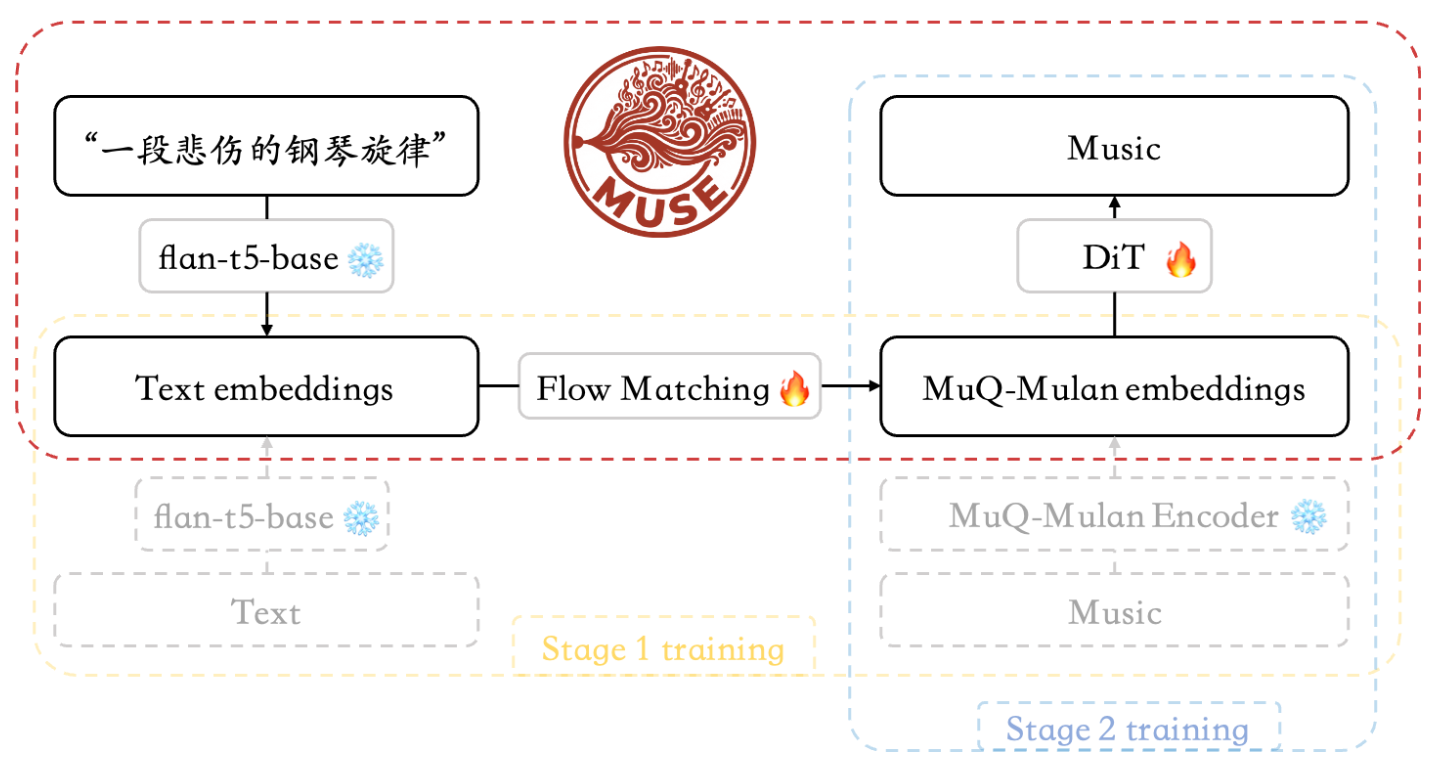
Two-Stage Architecture
Stage 1: Text2MuQFlow (271M params)
- Cross-attention Flow Matching
- Output: 512-dim MuQ-MuLan embedding
- 50-step ODE (dopri5 solver), CFG scale 3.0
Stage 2: StableAudioMuQ (1.05B params)
- Diffusion Transformer + Classifier-Free Guidance
- 100-step ODE sampling
- Output: 44.1kHz stereo, up to 47 seconds
Parallel Computing Highlights
| Challenge | Solution |
|---|---|
| Memory-heavy (1B+ params) | PyTorch DDP across 4×A800 GPUs |
| Compute-bound (100-step ODE) | Batch inference parallelization |
| I/O bottleneck (44.1kHz audio) | Cached MuQ embeddings |
Training Summary
| Stage | GPUs | Wall Time | GPU-hrs | Best Loss |
|---|---|---|---|---|
| Stage 1 | 2×A800 | ~8.2h | ~16 | 0.0569 |
| Stage 2 | 4×A800 | ~32h | ~128 | 1.078 |

Batch Inference Performance
The key insight: model size determines batching efficiency.
| Model Size | Batch Speedup | Reason |
|---|---|---|
| < 500M | 5-30× | GPU under-utilized |
| 500M-1B | 2-5× | Partial saturation |
| > 1B | ~1× | Already saturated |
Stage 1 (271M): 15× speedup at BS=16 — memory stays constant at 4.58GB Stage 2 (1.05B): 1.5× speedup at BS=16 — memory scales linearly (18→36GB)
End-to-End Result
- 42% time reduction for 16 samples (185s → 108s)
- Reproducible outputs (max diff < 1e-7)
MUSE Application
The full-stack application includes:
- 🎹 Studio: Text-to-music generation with batch sampling
- 🔬 Lab: Latent space exploration & interpolation
- 📚 Library: Audio management, tagging & playback
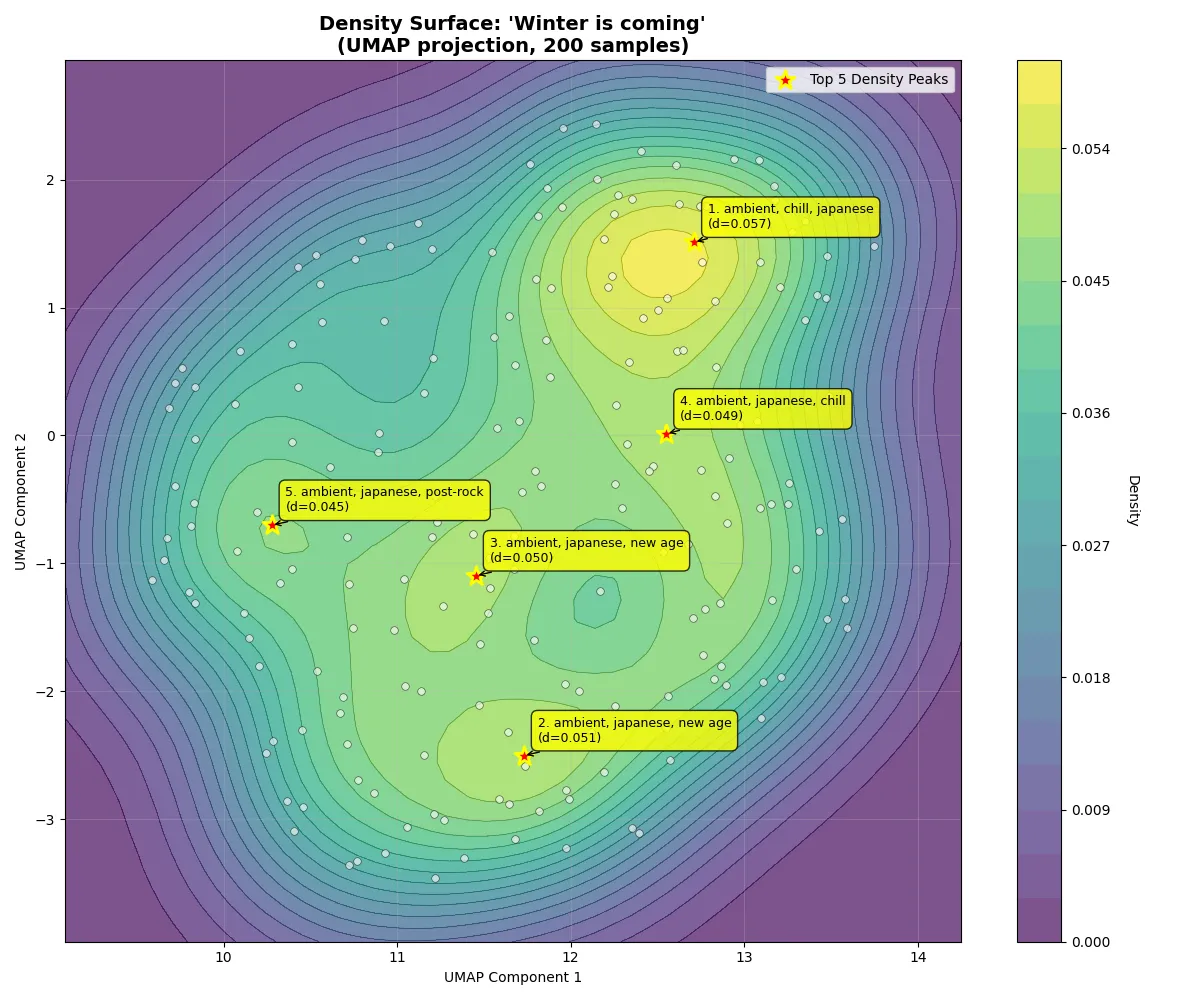 Diverse samples visualized in MuQ-MuLan latent space
Diverse samples visualized in MuQ-MuLan latent space
Tech Stack
Gradio · PyTorch · torchaudio · Plotly · UMAP